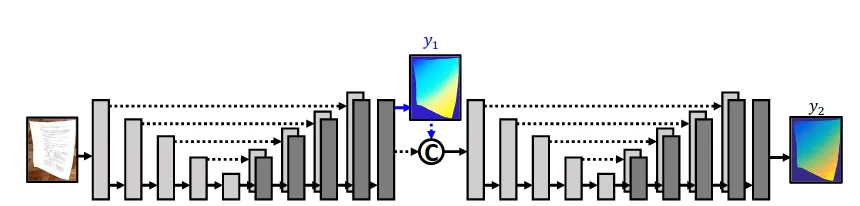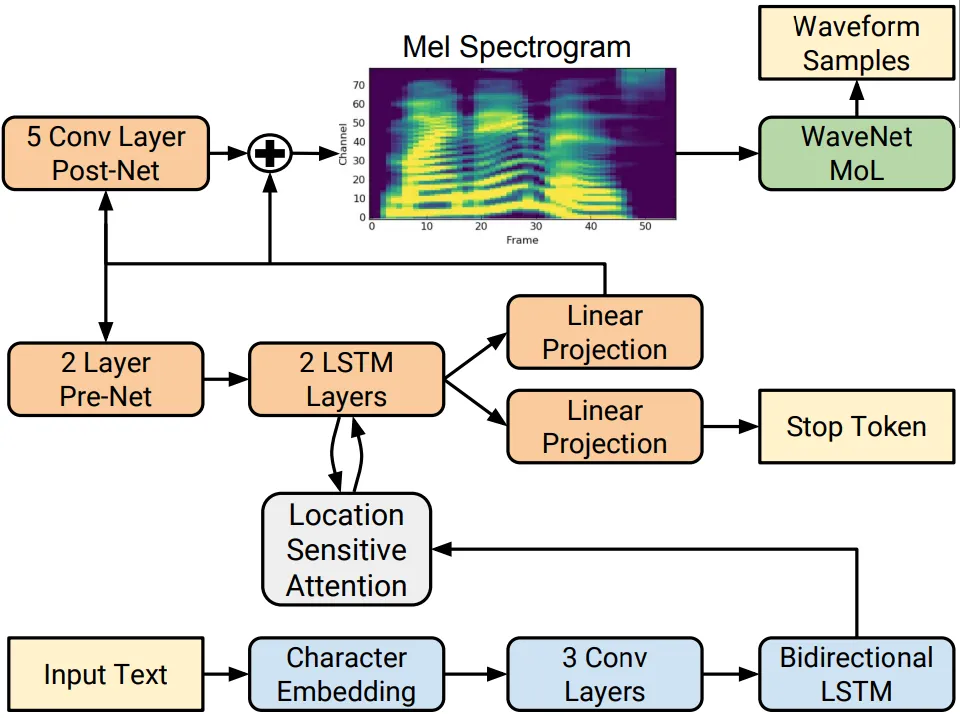
The recent improvements in the field of speech synthesis have lead to many innovative technologies, offering a wide range of useful applications like automatic speech recognition, natural speech synthesis, voice cloning, digital dictation, and so forth.
Deep learning has played an immensely important role in improving already existent speech synthesis approaches by replacing the entire pipeline process with neural networks trained on data alone.
Continue reading “An architecture for production-ready natural speech synthesizer”